Dynamic loading
: Disk -> 필요한것만 -> RAM
> Lib 로 code level ( OS X)
Dynamic Linking (shared libraries) // .dll
: system lib (ex) printf) ||| my code
> executive할때 link with stub
Stub
code 상의 printf : 0x1000 // 글자 상태 (점프용코드)
> branch
printf 실제구현 : 0x2000 // 함수형태
>> branch 과정 추가 -> 느림
Static Linking
: code + lib -> binary img
> 합쳐지므로 무거워짐 , lib 업데이트시 img 전체 빌드를 해야함
Contiguous Allocation
: Memory = OS + User
-> Relocation Registers wiht MMU
Base : 논리주소 0 의 시작
Limit : 크기
ex)
logical = 100
Base Regi = 4000
Limit Regi = 2000 // MAX logical // 초과시 trap
> 물리주소 시작= 100 + 4000 =0x4100
>> 연속적
Variable Partition

파란부분 : Hole (Free)
process N : allocation
> 알고리즘
First : 첫번째 hole
// 50% rule : 1/3 unusable
Best : 전부 할당후 Hole의 크기와 비슷한 -> 검색시간큼 <> 자잘한 hole들
Worst : " 많이남은 -> Fragmentation : 큰부분들의 쪼개짐
Fragmentation
: 공간은 있지만 쪼개져 버려서 사용X
External : ∑hole > request // 연속x
> Compaction , Paging/Segmentation
Internal : 메모리할당 > request
by Paging
> 4kb(page) ,6kb 요청
> 2page with 2kb 낭비
Compaction : Hole 들 합침
> 앞쪽으로 Processes 이동
조건) relocation : dynamic , 실행시간 내에 끝나야함
> Process를 잠깐 멈추고 물리주소 재배
문제) I/O (OS buffer) 중에는 변경X
Backing store : many swap -> Fragmentation 생김
Paging
각 process 의 메모리를 작은 블록으로 나누며 각각의 PageTable이 있음
: logical(Page) -> MMU -> PageTable(memory) -> physical(Frame)
장) External Fragmentation X : 모두 같은 page size
단) PageTable > OverHead, 시간
Internal Fragmentation O : 마지막Page는 채워지지 않을수도

CPU logical Address : m = PageNumber(p,m-n) + page offset(n,d)
> PT) frameNumber + offset
= Physical Address

n=2 , m=4
> Page Size : 2^2 = 4byte
logical : 16byte
>
m-n = 2
> p(PageNumber)= 4byte
>>
4byte 당 1page !
Calculating internal fragmentation
Page size = 2,048 bytes //2kb
Process size = 72,766 bytes
> 35 pages+ 0.53page // 0.53page * 2kb= 1,086 bytes
Internal fragmentation of 2,048 - 1,086 = 962 bytes
> 1 page 내 남는공간
Worst case fragmentation = 1 frame – 1 byte
> 가장 나쁜 경우 -> 1byte 때문에 paging
+
On average fragmentation = 1 / 2 frame size
> 경험상 평균적 fragment
>>
frame size를 줄이자!
> page table이 너무커짐 //physical Memory에 있음
>>>
page size 를 늘림 : 8kb
// frame size == page size
// > 그래야 1:1 mapping
Page Table // in Physical Memory
> PTBR : Base Regi
> PTLR : length Regi

TLBs ( translation look-aside buffers ) (= associative memory)
: HW cache -> 최근 참조 가상<-> 물리 변환정보 저장
: CPU logical -> MMU -> TLB -> Memory
> Hit : 성공 // 메모리 access :1번
> Miss : PageTable을 거침 // PT + 물리주소 : 2번
+ ASIDs : 어떤 P에서 어떤 request
> C/S 시 Flush (TLB비움) 방지
with Wired down
EAT (effective Aceess Time)
ex) Hit: 80% , Memory Aceess :10ns > 0.80 * 10 +0.20 * 10*2 = 12ns > 100% 일때에 비해 20% slow// TBL locality -> 보통 Hit 90%이상
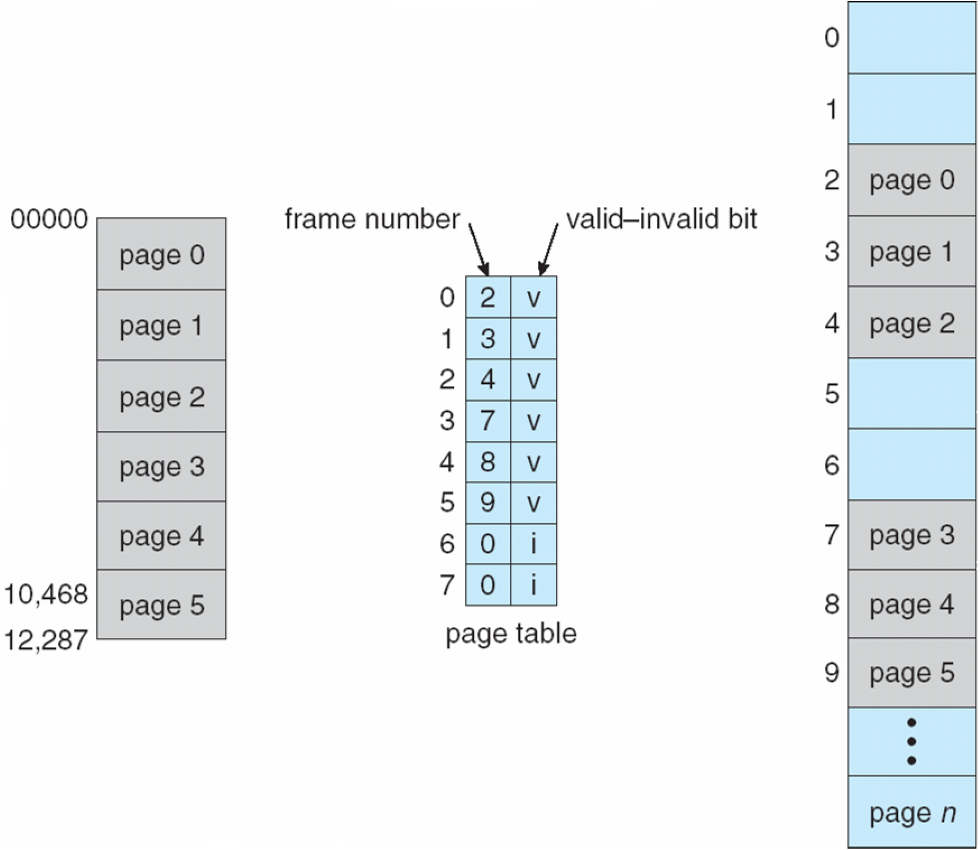
Memory Protection
: frame number + N Protection bit : V/ I/ RO/ RW/ XO
+ invalue -> mapping X
> PTLR을 맞춰 조절 -> 초과못하도록 보호