Histogram of CPU-burst durations
> 대부분 (80%)의 CPU burst(execution time) 은 8ms 로 집중
preemptive (선점형)
높은 우선순위가 오면 멈추고 내어줌
// Race Condition : 우선순위로 계속 밀려서 기아 상태
<> NON : 높은놈와도 계속함
1. Scheduler : 어떤 core에 어떤 Task 넣어줄지 선택,계획
C/S..
2. Dispatcher : 스케쥴링된 Task에 CPU를 실제로 할당
스케쥴링 단위
1. CPU utilization : CPU 가 얼마나 바쁜지
2. Threoughput : 단위 시간당 얼마나 많은 Task를 실행하는지
3. TurnAround Task(TAT) : Process의 도착~완료 까지의 시간
4. Waiting time(WT) : Ready Queue 내의 Task 의 대기시간
5. Response time : Request 실행 > 첫 respone 까지의 시간
//보통은 5 == 3
// ex) sorting : 첫번째 정렬값이 나오는 time
>
1,2 : MAX , 3,4,5 : Min 이 좋은 case
// 많은걸 한번에 및 짧게 대기
스케쥴링 알고리즘
1. FCFS (Come, Served //FIFO ~= 줄서기)
> Convoy Effect : FCFS 에서는 BurstTime 이 짧은것부터 실행! // 최적화
2. SJF (shortest Job First) : burst time 작은것부터 // optimal
> CPU Burst Time 을 User 에게 ask OR 예측함.. > 쓰기 어려움
> 1. 예측 2. 정렬 3. 배치
> 이전과 비슷할것이라 예측

// t : tn
// T : 타우
// α : 예측값 : 0.5 로 보통 셋팅
1. α = 0 // 예측X
> Tn+1 =Tn : 현재를 앞으로도 쭉 반영
// P1 <- 10 , p2 =10, p3=10
2. α = 1 // Full 예측
: Tn+1 = α tn : 이전 값을 그대로 반영
// Pn=1 :10 -> 미래 :10
// Pn=2 : 8 > 미래 : 8
// Pn=3 : 7 > 미래 : 7
3. a=1/2
τn+1=αtn+(1−α)αtn−1+(1−α)^2 αtn−2+…
> 예측에는 가장 가까웠던 (n) 의 Burst Time 영향이 제일큼
> α = 0.5 > 과거값이 계속 깎여나감
3. 선점형 SJF (shortest_remaning_time first)
A B // A: Arive , B : Burst
P1 0 8
P2 1 4
P3 2 9
P4 3 5
: B-T 가 짧은놈이 우선순위
RR (Round Robin)
: Tasks 을 순차적으로 q 만큼 돌아가며 실행
> q (time quantum) : 10~100ms // 최근 10us
> Program의 Max Wait : (n-1)q
>> P1 에서 Q만큼 하고 C/S 한뒤 P2
: Q > C/S time : FIFO 방식으로 잘 동작
<> Q < C/S time : 수행 시간보다CS Time 이 더큼 -> 성능 X
>특징)
1. 한 core 가 오랫동안 Burst Time 갖는걸 방지
2. Q 만큼의 시간만큼은 실행 보장
but 높은 TAT : B-T 가클경우 여러번의 W-T
> Q 가 크면 TAT 시간 극복
Priority Scheduling (우선순위) with SJF
// SJF : BurstTime 이 길수록 나중에 // Convoy effect
>but) Starvation (Race condition) : 우선순위가 낮으면 계속 wait 가능성
>> Aging 기법! : 오래 기다릴수록 우선순위를 점점 높이는 기법
// 일반적인 OS : Priority + RR Scheduling
// : 우선순위대로 하되 q 시간만큼만!
MultiLevel Queue
: Prioriy 마다 각각의 Queue 가 존재
ex) Priority = 0 : T1,T2,T3,,,
Priority = 1 : T4,T5,T6,,,
// 다른 Priority 의 Queue에 들어갈수없음
Process별 Priority 유형(type)
1. RT process // RealTime Process
2. System Process // OS scheduler ,,
3. Interactive Process // 짧은 I/O 그에 따른 간단한Computation
4. batch //주기적, 대량
MultiLevel FeedBack Queue
> 한 Process 가 Queue 들을 옮겨다님
> Aging도 구현 가능! // 오래된걸 위로 올리는식으로
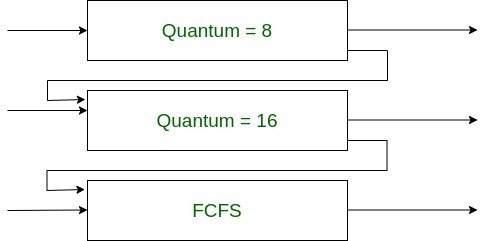
ex) Q0 : RR , Q=8
Q1 : RR , Q=16
Q2 : FCFS (FIFO)
Q0 에서 안끝나면 Q1
> 안끝나면 Q2
> 안끝나면 FCFS로 먼저온순을 쭉 보내는(Aging) 방식
Thread Scheduling
User ) n:1, n:n (lib) PCS (process_condition_scope)
> User 에서 Kernel 이 필요할때
> process 내에서 ULT 끼리 경쟁!
Kernel) 1:1 SCS (system " " )
> 전체 시스템의 여러process들의 Thread끼리 경쟁! // CS 를 통해 전환!
// LINUX ,MAC 방식